Now, where did I put that document again?
 Any organisational system is only as good as how easy it is to find the material you are looking for, and this system is no different. But sometimes it can feel like trying to find a needle in a haystack. I think we have all been there, after all that is why the meme works so well. While in my first system the organisation was a mess of folder tabs and hanging files, my later, early digital, systems involved portable usb sticks, complex synchronisation scripts, and a plethora of duplicated files. However, this current system is a lot more streamlined, easy to use, and relatively simple in practice. It involves just two applications, that link into my overall structure: Dropbox, and DEVONthink.
Any organisational system is only as good as how easy it is to find the material you are looking for, and this system is no different. But sometimes it can feel like trying to find a needle in a haystack. I think we have all been there, after all that is why the meme works so well. While in my first system the organisation was a mess of folder tabs and hanging files, my later, early digital, systems involved portable usb sticks, complex synchronisation scripts, and a plethora of duplicated files. However, this current system is a lot more streamlined, easy to use, and relatively simple in practice. It involves just two applications, that link into my overall structure: Dropbox, and DEVONthink.
Dropbox
Dropbox is a bit of a staple of many organisational systems, being one of the early cloud file storage services. However, even now I am constantly surprised by the number of people who don’t use a cloud synced service like Dropbox, and even more surprisingly have never heard of the option. While having a cloud synced storage option is not completely needed, it is an excellent way to work. In my broader environment I have three machines, two laptops and a desktop. The laptop on my desk at college is an older Macbook Pro, which I am happy to leave just locked in an office. On the other hand my desktop and new rMBP are a bit more precious and generally stay at home or within eyesight. This does present a bit of a problem though, how to transfer files around. What happens if I am reading a document at home, and then head into college and it isn’t there. Well that is where Dropbox steps in. To be able to find the needle in the haystack, you first have to have an accessible haystack.
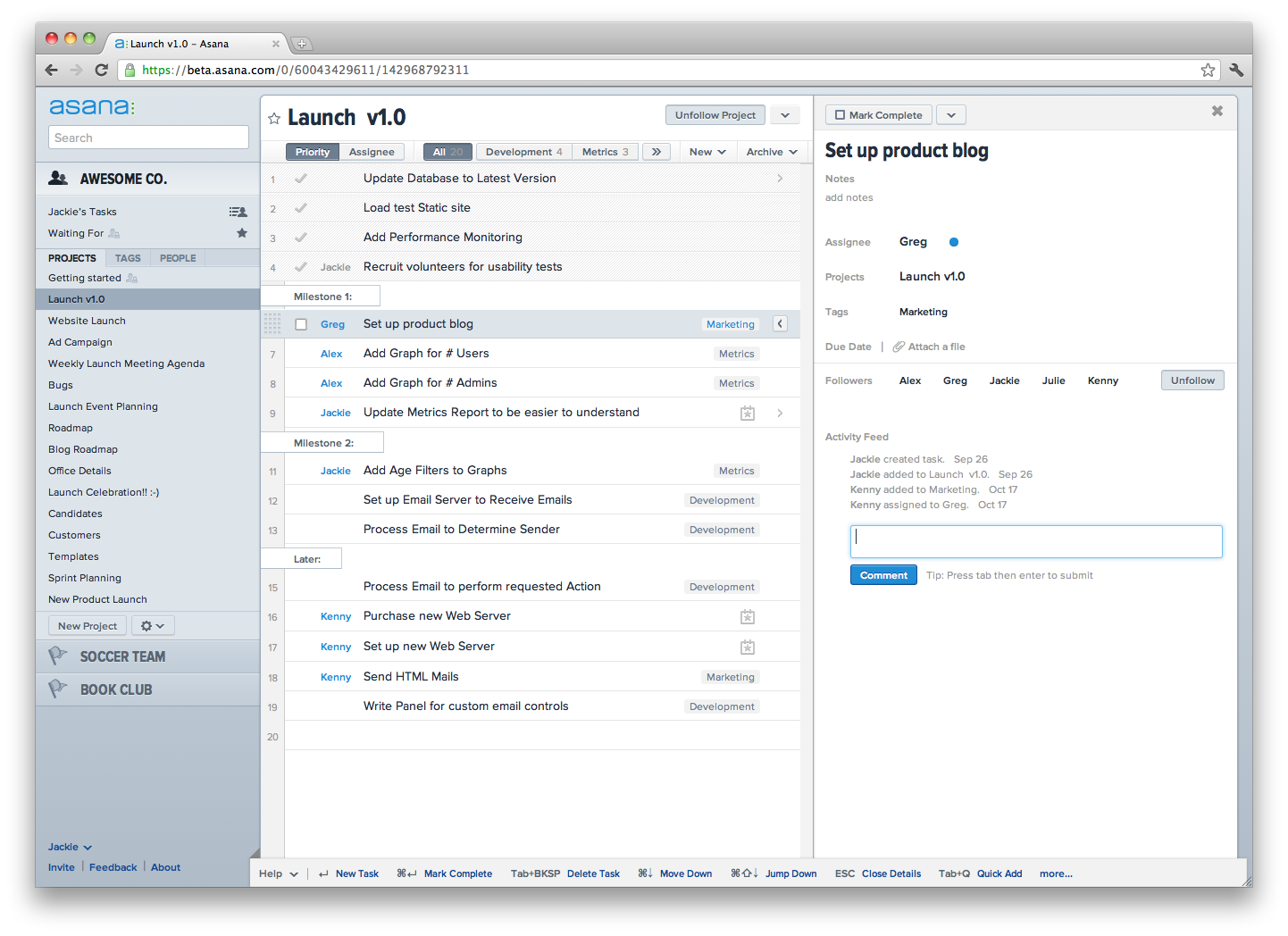
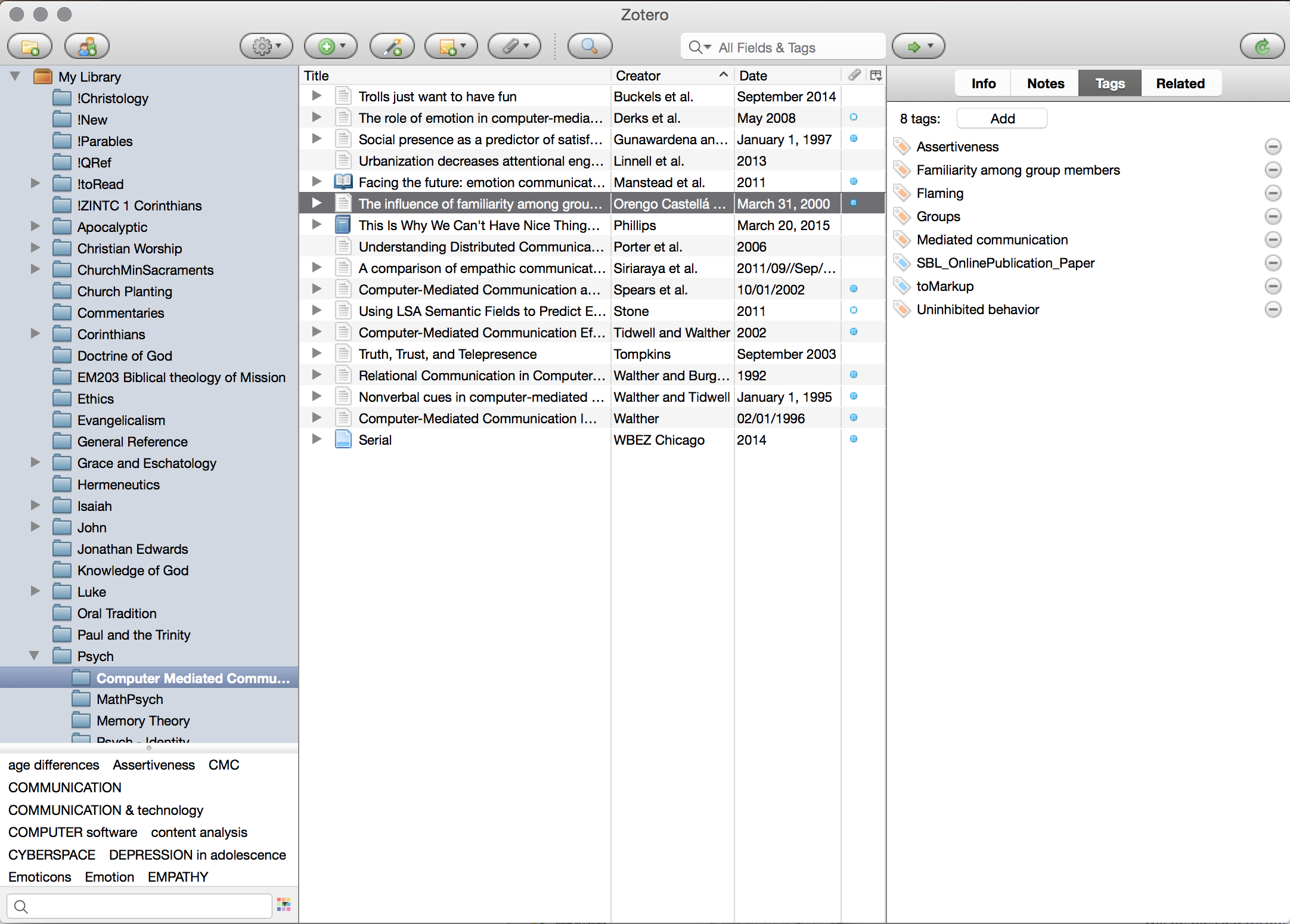
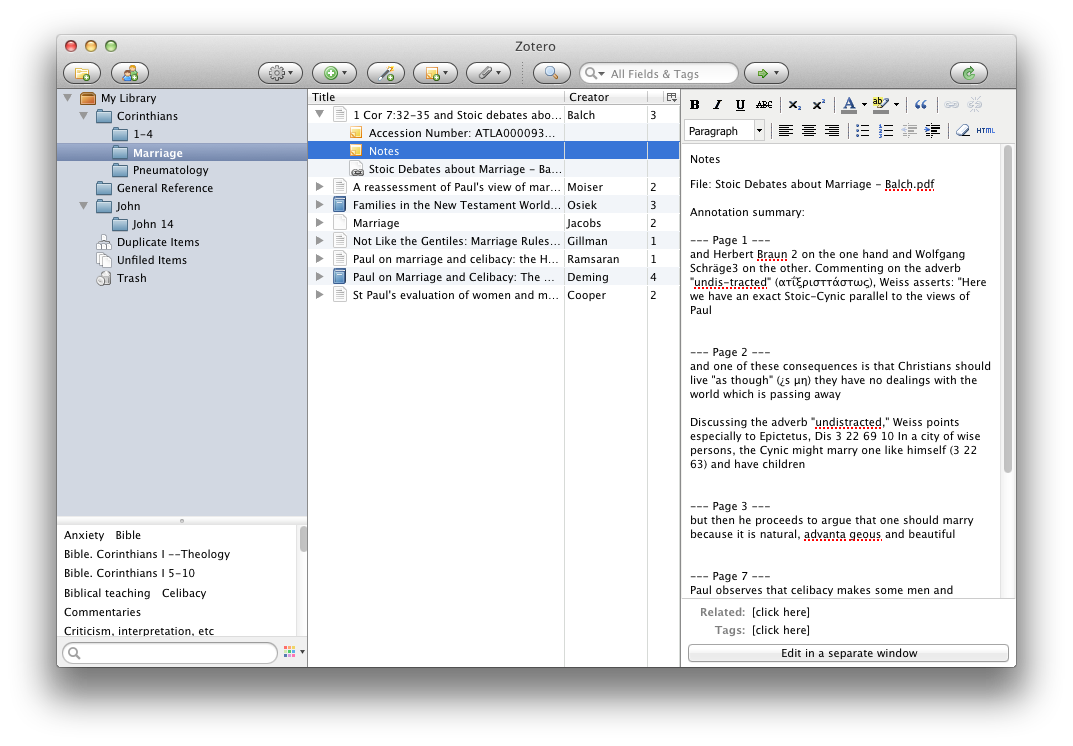
Basically Dropbox works by synchronising everything you place in its folder into the cloud, and then replicating that sync to each machine. Its pretty simple really. While there are a ton of services that offer this feature, I started with Dropbox and given that it hasn’t eaten all my documents yet, I’m happy to stay with it. There are a ton of other features of Dropbox, such as shared folders (Gill and I use this regularly), and a bunch more. But the basic functionality that I use is simply to share files around the place. Now one of the reasons that I have stuck with Dropbox is that as an early service provider it is generally also supported by other applications, like GoodReader on my iPad which I will look briefly at next week. Having other app support is quite critical in some ways, so I would encourage you to find an app that works with everything that you want to work with. The key to working with Dropbox is to have a good folder organisation system. You can see mine in the screenshot, and it works for me. I recommend that you sit down for a bit and try and figure out a logical structure early on. They can be changed later, but the earlier you start with a structure the more natural it feels. As a little side note, if you want to have a folder appear at the top of a listing every time then just put an ! at the start of the folder name, as you can see from my screenshot.
The other bonus with Dropbox is that it provides a good backup service. When your laptop goes missing, or Word eats a document, then you don’t have to worry as much about losing everything. Quick story time:
Years ago when I was working in IT Support at the John Curtin School of Medical Research, I had a PhD student come to me in a panic. He was lugging his PC along with him, and to cut a longer story short the machine had been fried in an unfortunate lightning strike. Now he had all of his digitised data on that machine, and I do mean ALL of his data. From chapters of his thesis through to the raw data that made up his workings. Furthermore, he was somewhat paranoid about someone stealing his research and so while he kept notebooks for lab sessions, he destroyed the data after he had digitised it. Oh and he had no backups. That’s right, NO backups. Thankfully we could restore a bit of his data, but he still lost around 8 months worth of work. Moral of that story: back up your data!
Dropbox is handy here, while I don’t advocate it as a complete backup service (and it shouldn’t be treated as such), it does provide a medium layer of backup, and a bit of piece of mind.
Still make sure you BACKUP EVERYTHING. Email it to yourself, have multiple copies across multiple machines. Print it out if needed. But make sure you backup.
If you haven’t heard of Dropbox, or you haven’t signed up, then I’m going to do something unusual for this blog. I’m going to give a referral link. Basically if you use this link then both you and I get a bit of extra space. Its not a lot, but it is better than a slap in the face with a wet fish. So if by some oddity you haven’t signed up for Dropbox, then go here: https://db.tt/MffoWBy
DEVONthink
Onto the next little app: DEVONthink. If Zotero is your reference and research database, then DEVONthink is your ‘Google.’ This app is probably a bit of an optional extra for most readers, as a lot of its usage depends on how you remember things. Personally I have a really good priming memory, and so tend to remember random quotes or bits of articles. DEVONthink essentially works as a large and relatively smart search engine for my local machine. I get it to index my entire research library, and then you can execute searches within that database.
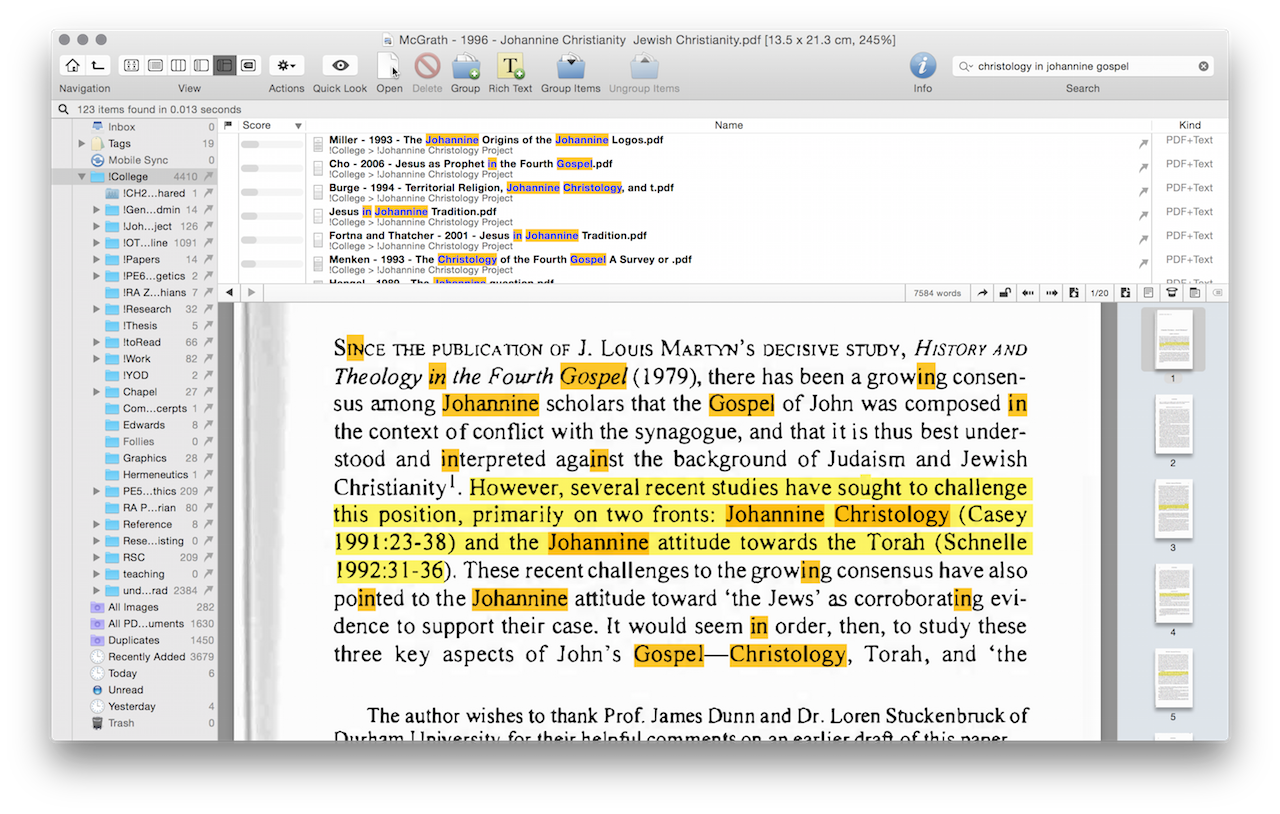
Now if you have all your scanned files OCRed into searchable text, then you can find pretty much anything within your library relatively quickly. In addition it has a decent inference language search engine, so that it can tell you which documents are related to your search terms, even if it doesn’t use that exact phrase.[ref]Pretty sure it uses a modified LSA algorithm here[/ref] This is only scratching the surface of DEVONthink, as it supports tagging, metadata and much more. However, given it is only an optional extra, I wont go into it in a huge amount of detail. My main usage for DEVONthink is to leverage my own memory type, and so while it makes sense for me it may not for you. If you don’t need such fine grained searching then its quite likely that the built in Spotlight search in OSX will work for you.
Thats it for this shorter post this week. Although I am interested in how other people find data in their storage database. Comment below.














 One of the best ways to get those writing juices flowing is to write regularly. I know quite a few people who simply set aside a couple of hours a day in their schedule to write. In that writing time they simply write on whatever is currently on the agenda. It could be for a paper, or project, or a conference; so long as it is writing. The dedicated time set aside helps to get a little bit done every day. However, for me this isn’t optimal, as some days with the little man I barely get a chance to write at all. For me I instead aim to write a certain amount per day, a task focused goal rather than time focused. While I don’t dedicate time, I do set myself a task every day to be written. This type of regularity works better with my schedule, and my thought processes. But whichever one you do it gets you writing regularly, and set it as a goal. As Bandura showed, short term goal setting increases the motivation for the task.[ref]Bandura, Albert. Self-Efficacy: The Exercise of Control. New York: Freeman, 1997.[/ref]
One of the best ways to get those writing juices flowing is to write regularly. I know quite a few people who simply set aside a couple of hours a day in their schedule to write. In that writing time they simply write on whatever is currently on the agenda. It could be for a paper, or project, or a conference; so long as it is writing. The dedicated time set aside helps to get a little bit done every day. However, for me this isn’t optimal, as some days with the little man I barely get a chance to write at all. For me I instead aim to write a certain amount per day, a task focused goal rather than time focused. While I don’t dedicate time, I do set myself a task every day to be written. This type of regularity works better with my schedule, and my thought processes. But whichever one you do it gets you writing regularly, and set it as a goal. As Bandura showed, short term goal setting increases the motivation for the task.[ref]Bandura, Albert. Self-Efficacy: The Exercise of Control. New York: Freeman, 1997.[/ref]


 Ultimately though, as even William Zinsser admits ‘Writing is hard work.’ But if we write regularly, then the process comes a bit more easily, and rather than focusing on the writing task we can focus on writing style, which is arguably even more important. After all how can one edit and refine their work if there is no work there to edit in the first place. So focus first on getting words out on the screen or page and then perfecting them. Undoubtedly they wont come out exactly right the first time, or the second, or even perhaps the third, but get something out so you can work with it. In the vein of Confucious or Yoda, ‘to write a lot, you first have to write.’ Next week we will take a look at the second aspect of writing: style.
Ultimately though, as even William Zinsser admits ‘Writing is hard work.’ But if we write regularly, then the process comes a bit more easily, and rather than focusing on the writing task we can focus on writing style, which is arguably even more important. After all how can one edit and refine their work if there is no work there to edit in the first place. So focus first on getting words out on the screen or page and then perfecting them. Undoubtedly they wont come out exactly right the first time, or the second, or even perhaps the third, but get something out so you can work with it. In the vein of Confucious or Yoda, ‘to write a lot, you first have to write.’ Next week we will take a look at the second aspect of writing: style.

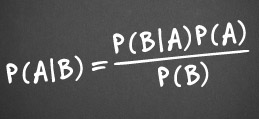

 So what can be done about it? Well this blog post is one useful step. Being aware of the backfire effect should help us evaluate our own belief systems when we are challenged with contradictory evidence. After all we are just as susceptible to the backfire effect as any other human being. So we should be evaluating ourselves and our own arguments and beliefs, and seeing where our Bayesian inference leads us, with the humility that comes from the knowledge of our own cognitive biases, and the fact that we might be wrong. However, it should also help us to sympathise with those who we think are displaying the backfire effect, and hopefully help us to contextualise and relate in such a way that defuses some of the barriers that trigger the backfire effect.
So what can be done about it? Well this blog post is one useful step. Being aware of the backfire effect should help us evaluate our own belief systems when we are challenged with contradictory evidence. After all we are just as susceptible to the backfire effect as any other human being. So we should be evaluating ourselves and our own arguments and beliefs, and seeing where our Bayesian inference leads us, with the humility that comes from the knowledge of our own cognitive biases, and the fact that we might be wrong. However, it should also help us to sympathise with those who we think are displaying the backfire effect, and hopefully help us to contextualise and relate in such a way that defuses some of the barriers that trigger the backfire effect.









 Furthermore this is only exacerbated when it is brought into a social setting. While the nature of the FAE is powerful on an individual level it is stronger again amongst groups. The expanded bias, creatively named Group Attribution Error, sees the attributes of the out-group as being defined by individual members of that group. We met this bias briefly in the post a couple of weeks ago on Cyclists vs Motorists and Intergroup biases. This is further expanded again with Pettigrew’s, again creatively named, Ultimate Attribution Error (one must wonder where to go after this). While FAE and GAE look at the ascription to external and out-groups primarily and discard most internal and in-group data, Ultimate Attribution Error seeks to not only explain the demonisation of out-group negative actions, but explain the dismissal of out-group positive behaviours. Interestingly many of the studies that support Pettigrew’s Ultimate Attribution Error look at religio-cultural groups as their case studies, such as the study by Taylor and Jaggi (1974), or later studies on FAE/UAE and suicide bombing (Altran, 2003).
Furthermore this is only exacerbated when it is brought into a social setting. While the nature of the FAE is powerful on an individual level it is stronger again amongst groups. The expanded bias, creatively named Group Attribution Error, sees the attributes of the out-group as being defined by individual members of that group. We met this bias briefly in the post a couple of weeks ago on Cyclists vs Motorists and Intergroup biases. This is further expanded again with Pettigrew’s, again creatively named, Ultimate Attribution Error (one must wonder where to go after this). While FAE and GAE look at the ascription to external and out-groups primarily and discard most internal and in-group data, Ultimate Attribution Error seeks to not only explain the demonisation of out-group negative actions, but explain the dismissal of out-group positive behaviours. Interestingly many of the studies that support Pettigrew’s Ultimate Attribution Error look at religio-cultural groups as their case studies, such as the study by Taylor and Jaggi (1974), or later studies on FAE/UAE and suicide bombing (Altran, 2003).

 Things
Things